。然而,由于依赖于聚类的质量,当(1)具有相同语义类的附近对象被打包在一起,或(2)具有松散连接区域的大型对象时,这些方产生容易受到影响的结果。为了解决这些限制,我们引入了 ISBNet,这是一种新颖的cluster-free方法,它将实例表示为内核并通过动态卷积解码实例掩码。为了有效地生成高召回率和判别力的内核,我们提出了一种名为“实例感知最远点采样”的简单策略来对候选进行采样,并利用受 PointNet++ 启发的本地层对候选特征进行编码。此外,我们还表明,在动态卷积中预测和利用 3D 轴对齐边界框可以进一步提高性能。我们的方法在 SNetV2 (55.9)、S3DIS (60.8) 和 STPLS3D (49.2) 上的 AP 上设置了新的最先进结果,并保留了快速推理时间(ScanNetV2 上每个场景 237 毫秒)。
3D实例分割(3DIS)是3D领域深度学习的核心问题。给定由点云表示的 3D 场景,我们寻求为每个点分配语义类和唯一的实例标签。 3DIS 是一项重要的 3D 感知任务,在自动驾驶、增强现实和机器人导航等领域有着广泛的应用,其中可以利用点云数据来补充 2D 图像提供的信息。与 2D 图像实例分割 (2DIS) 相比,3DIS 可以说更难,因为外观和空间范围的变化更大,而且点云分布不均匀,即靠近物体表面密集而其他地方稀疏。因此,将 2DIS 方法应用于 3DIS 并非易事。
3DIS 的典型方法是 DyCo3D,采用动态卷积来预测实例掩码。具体来说,点被聚类、体素化,并通过 3D Unet 生成实例内核,用于与场景中所有点的特征进行动态卷积。这种方法如图 2 (a) 所示。然而,这种方法有一些局限性。首先,聚类算法严重依赖质心偏移预测,其质量在以下情况下显着恶化:(1) 对象密集,导致两个对象可能被错误地组合在一起作为一个对象,或 (2) 各部分连接松散的大型对象结果聚类在不同的对象中。这两种情况如图 1 所示。其次,点的特征主要编码对象外观,其不足以区分不同的实例,特别是在具有相同语义类的对象之间。这里也推荐「3D视觉工坊」新课程《三维点云处理:算法与实战汇总》。
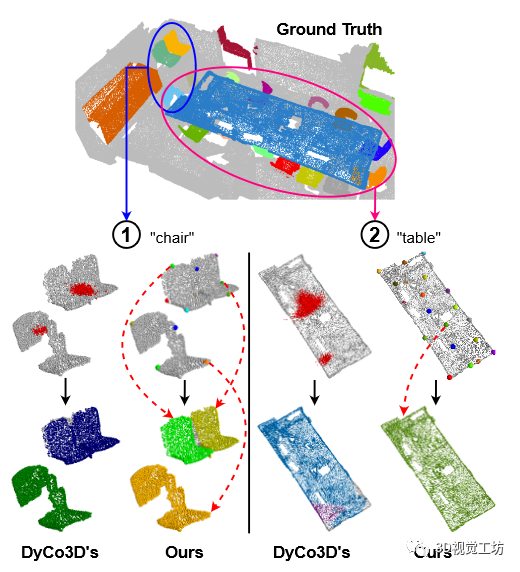
图 1. 在 DyCo3D中,内核预测质量很大程度上受到基于质心的聚类算法的影响,该算法有两个问题:1 对附近实例进行错误分组,2 将大对象过度分割成多个片段。我们的方法通过实例感知点采样解决了这些问题,取得了更好的结果。每个样本点都会聚合来自其本地上下文的信息,以生成用于预测其自己的对象掩码的内核,并且最终实例将由 NMS 进行过滤和选择。
为了解决 DyCo3D 的局限性,我们提出了 ISBNet,这是一种用于 3DIS 的无集群框架,具有实例感知最远点采样和框感知动态卷积。首先,我们重新审视最远点采样(FPS)和大量聚类方法,发现这些算法产生的实例召回率相当低。结果,在后续阶段遗漏了许多对象,导致性能不佳。受此启发,我们提出了实例感知最远点采样(IA-FPS),其目的是在具有高实例召回率的 3D 场景中对查询候选进行采样。然后,我们介绍点聚合器,将 IA-FPS 与本地聚合层结合起来,将实例的语义特征、形状和大小编码为实例特征。
此外,对象的 3D 边界框是现有的监督,但尚未在 3D 实例分割任务中进行探索。因此,我们在模型中添加一个辅助分支来联合预测每个实例的轴对齐边界框和二进制掩码。地面实况轴对齐边界框是从现有实例掩码标签推导出来的。与 Mask-DINO和 CondInst不同,辅助边界框预测仅用作学习过程的正则化,我们将其用作动态卷积中的额外几何线索,从而进一步提高了实例分割任务。
为了评估我们方法的性能,我们对三个具有挑战性的数据集进行了广泛的实验:ScanNetV2 、S3DIS和 STPLS3D。 ISBNet 不仅在这三个数据集中实现了最高的准确率,在 ScanNetV2、S3DIS 和 STPLS3D 上超过了最强的方法 +2.7/3.4/3.0,而且还表现出很高的效率,在 ScanNetV2 上每个场景的运行时间为 237ms。总而言之,我们的工作贡献如下:
(i) 我们提出了 ISBNet,一种 3DIS 的cluster-free范例,它利用实例感知的最远点采样和点聚合器来生成实例特征集。
(ii) 我们首先介绍使用轴对齐边界框作为辅助监督,并提出框感知动态卷积来解码实例二进制掩码。
(iii) ISBNet 在三个不同数据集上实现了最先进的性能:ScanNetV2、S3DIS 和 STPLS3D,无需对每个数据集的模型架构和超参数调整进行全面修改。
**2D 图像实例分割 (2DIS) **涉及为图像中的每个像素分配实例标签和语义标签之一。它的方法可以分为三组:基于提案的方法、无提案的方法和基于 DETR 的方法。对于基于提案的方法 ,利用对象检测器(例如 Faster-RCNN)来预测对象边界框,以分割检测到的框内的前景区域。对于无提议方法,SOLO 和 CondInst 使用特征图预测动态卷积的实例内核以生成实例掩码。对于基于 DETR 的方法 ,Mask2Former和 Mask-DINO采用带有实例查询的转换器架构来获取每个实例的分割。与 3DIS 相比,由于 2D 图像的结构化、基于网格和密集的特性,2DIS 可以说更容易。因此,将 2DIS 方法应用于 3DIS 并非易事。
感兴趣的是使用语义类和唯一实例 ID 来标记 3D 点云中的每个点。它们可以分为基于提议的方法、基于聚类的方法和基于动态卷积的方法。
基于提案的方法首先检测 3D 边界框,然后分割每个框内的前景区域以形成实例。 3D-SIS 将 Mask R-CNN 架构应用于 3D 实例分割,并联合学习 RGB 图像和 3D 点云两种模式的特征。 3D-BoNet从总结场景内容的全局特征向量中预测固定数量的 3D 边界框,然后分割每个框内的前景点。这种方法的局限性在于,实例掩模的性能很大程度上取决于 3D 边界框的质量,由于 3D 点云的巨大变化和不均匀分布,3D 边界框非常不稳定。
基于聚类的方法学习潜在嵌入,有助于将点分组到实例中。 PointGroup预测从每个点到其实例质心的 3D 偏移,并从两个点云获取簇:原始点和质心偏移点。 HAIS提出了一种层次聚类方法,其中小簇可以被较大的簇过滤掉或吸收。 SoftGroup提出了一种软分组策略,其中每个点可以属于具有不同语义类别的多个簇,以减轻语义预测误差。基于聚类的方法的局限性之一是实例掩模的质量很大程度上取决于聚类的质量,即质心预测,这是非常不可靠的,特别是当测试对象在空间范围上与训练对象有很大不同时。
基于动态卷积的方法通过生成内核,然后使用它们与点特征进行卷积来生成实例掩码,来克服基于提案和基于聚类的方法的局限性。 DyCo3D采用中的聚类算法来生成动态卷积的内核。 PointInst3D使用最远点采样来代替中的聚类来生成内核。 DKNet [38]引入候选挖掘和候选聚合来为动态卷积生成更具辨别力的实例内核。
我们的方法是一种基于动态卷积的方法,在内核生成和动态卷积方面有两个重要的改进。特别是,在前者中,我们提出了一种新的实例编码器,将实例感知的最远点采样与点聚合层相结合,以生成内核来取代 DyCo3D 中的聚类。在后者中,我们不仅使用动态卷积的外观特征,还使用几何提示(即边界框预测)增强了该特征。
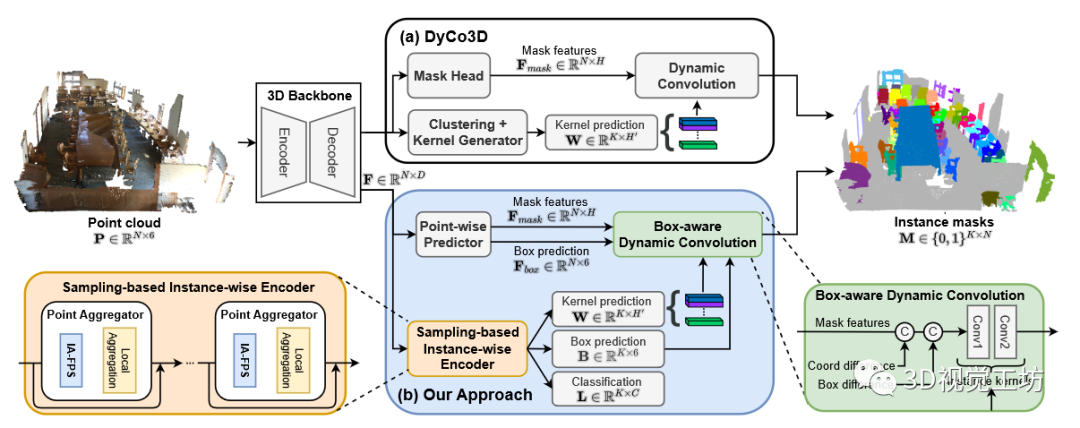
图 2. DyCo3D 的总体架构(块 (a))和我们的 3DIS 方法(块 (b))。给定点云,使用 3D 主干来提取每点特征。对于 DyCo3D,它首先根据每个点的预测对象质心将点分组为簇,为每个簇生成一个内核。同时,掩模头将每点特征转换为掩模特征以进行动态卷积。对于我们的 ISBNet 方法,我们用一种新颖的基于采样的实例编码器替换了聚类算法,以获得更快、更鲁棒的内核、框和类预测。此外,逐点预测器取代了 DyCo3D 的掩码头,以输出掩码和框特征,用于新的框感知动态卷积,以生成更准确的实例掩码。
问题陈述:给定一个 3D 点云,其中 N 是点的数量,每个点由 3D 位置和 RGB 颜色向量表示。我们的目标是将点云分割成 K 个实例,这些实例由一组二进制掩码 和一组语义标签表示,其中 C 是语义类别的数量。
我们的方法由四个主要组件组成:3D 主干网络、逐点预测器、基于采样的实例编码器和盒感知动态卷积。 3D 主干网采用 3D 点云作为输入来提取每个点特征。我们的主干网络提取特征其中 i = 1,... , N 为输入点云的每个点。我们遵循之前的方法,采用带有稀疏卷积 的 U-Net 作为主干。逐点预测器从主干网络获取每点特征并将其转换为逐点语义预测、轴对齐边界框预测 和用于框感知动态卷积的掩模特征。基于采样的实例级编码器(第 3.1 节)处理逐点特征以生成实例内核、实例类标签和边界框参数。最后,盒子感知动态卷积(第 3.2 节)获取实例内核和掩码特征以及互补框预测,以生成每个实例的最终二进制掩码。我们的方法的概述如图 2 所示。
给定主干网输出的每点特征 ,我们的目标是产生实例特征,其中 K ≪ N 。实例特征E被用于预测实例分类分数 、实例框和实例内核,其中 H′ 由动态卷积中卷积层的大小决定。
通常,可以采用最远点采样 (FPS)对一组 K 个候选进行采样,以生成实例内核。 FPS 通过使用成对距离选择距先前采样点最远的下一个点来贪婪地采样 3D 坐标中的点。然而,这种采样技术较差。首先,FPS采样的K个候选点中有很多属于背景类别的点,浪费了计算资源。其次,大物体在采样点的数量中占主导地位,因此不会从小物体中采样任何点。第三,逐点特征无法捕获本地上下文来创建实例内核。我们在选项卡中提供分析。 1 来验证这一观察结果。特别是,我们计算了内核预测的实例数量相对于总的真实实例的召回率。召回值应该很大,因为我们期望对真实实例上的聚类或采样点进行良好的覆盖。然而,可以看出,以前的方法的召回率较低,这可以解释为这些方法没有考虑点聚类或采样的实例。
为了解决这个问题,我们提出了一种新颖的基于采样的实例编码器,它在点采样步骤中考虑了实例。受 PointNet++中的Set Abstraction的启发,我们指定实例编码器包含一系列点聚合器 (PA) 块,其组件是实例感知 FPS (IA-FPS),以对覆盖尽可能多的前景对象的候选点进行采样,并且本地聚合层捕获本地上下文,从而单独丰富候选特征。我们将图 2 中橙色块中的 PA 可视化,并在下面详细介绍我们的采样。
实例感知 FPS。我们的采样策略是对前景点进行采样,以最大程度地覆盖所有实例,无论其大小如何。为了实现这一目标,我们选择如下迭代采样技术。具体来说,候选者是从一组点中采样的,这些点既不是背景也不是先前采样的候选者选择的。我们使用逐点语义预测来估计每个点成为背景的概率。我们还使用由前 k 个候选生成的实例掩码。利用 FPS 从点集 P′ ⊂ P 中采样点:
实际上,在训练中,由于实例掩码预测不足以指导实例采样,因此从预测的前景掩码中一次性采样 K 个候选者。另一方。
fun88app
上一篇:三一重工2023年年度董事会经营评述
下一篇:我爸给我买了一套300万婚房男朋友爸妈当着我面把房

